Monitoring Sitemap of a Website Using a Crawler
Sitemap monitoring is currently in alpha and available in the Professional plan and above.
Table of Contents:
- What is a Sitemap?
- Why do you need a Sitemap crawler?
- How does Distill work for sitemap monitoring?
- How to create a Sitemap monitor?
- How to exclude links for crawling and monitoring?
- How to change the frequency of crawling?
- How to view and manage crawlers?
- How is crawler data cleaned up?
What is a Sitemap?
A sitemap is an essential tool that helps search engines understand the structure of a website and crawl its content. It usually contains all URLs of a website, including those that may not be easily discoverable by search engines or visitors.
Why do you need a Sitemap crawler?
There are different formats of sitemaps, but the most common and widely supported format is the XML sitemap. While XML sitemaps are widely used, they may not be updated regularly or generated automatically. So, if you want to receive updates about new links added to a website, monitoring its sitemap file may not reflect the current state, and you may be missing out on new or updated content.
To overcome this limitation, you can use Distill’s crawler to index all URLs on a website. A crawler navigates through a website, discovering and indexing pages just like a search engine would. This ensures that all URLs are extracted from the website, even the hidden or dynamically generated pages.
How does Distill work for sitemap monitoring?
You can keep track of URLs belonging to a particular website using sitemap monitoring. Distill achieves this by first creating a list of URLs through the use of crawlers. The crawlers start at the source URL and search for all links within it. These links are then added to a list, and the crawlers proceed to go through each link one by one, crawling them to search for any additional links on the new page. The crawlers continue this process, crawling all the links they find until there are no more left to crawl.
However, there are some exceptions to what links the crawlers will crawl. They will not crawl links outside of the website’s domain, links that are not a subpath of the domain, or links that match the regular expression mentioned in the Exclude option while adding. By following these rules, Distill is able to create a comprehensive and accurate list of all URLs belonging to a website that can be monitored for changes.
How to create a Sitemap monitor?
Distill monitors a sitemap of a website in two steps:
- Crawler - Finds out all the links present on a website and creates a list of crawled URLs. You can set up the frequency and exclusion for the crawlers at this stage.
- Monitor - Adds the crawled list of URLs for tracking. You can configure the monitor’s settings, like actions and conditions at this step.
Here are the steps that you can follow to monitor the sitemap:
-
Open the Watchlist from the Web app at https://monitor.distill.io
-
Click
Add Monitor->Sitemap.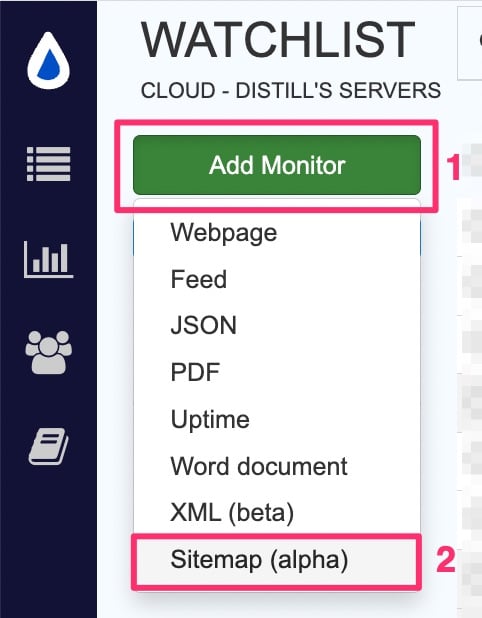
-
On the source page, add the Start URL. Links will be crawled from the same subdomain and the same subpath and not the full domain. So, you can add the URL from where you want to start the crawl. For example, if URL is https://distill.io, all subpaths like https://distill.io/blog, https://distill.io/help, etc will be crawled. But it will not crawl URLs like, https://forums.distill.io as it is a separate subdomain.
-
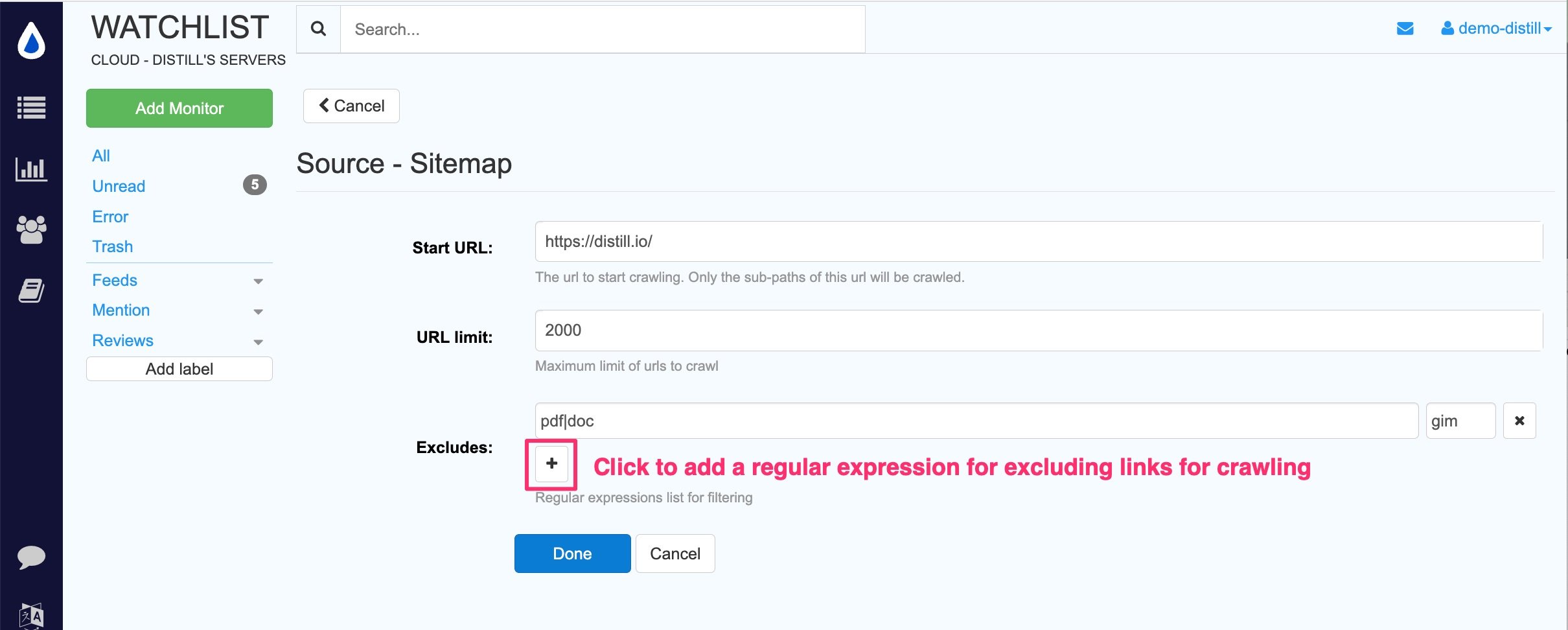
If you want to exclude any links for monitoring, you can use the regular expression filter as mentioned below for exclusion.
-
Click “Done”. It will open the Options page for the monitor’s configuration. You can configure actions and conditions at this page. Save when done.
Whenever URLs are added or removed from the sitemap you will get a change alert. You can view the change history of a sitemap monitor by clicking on the preview.
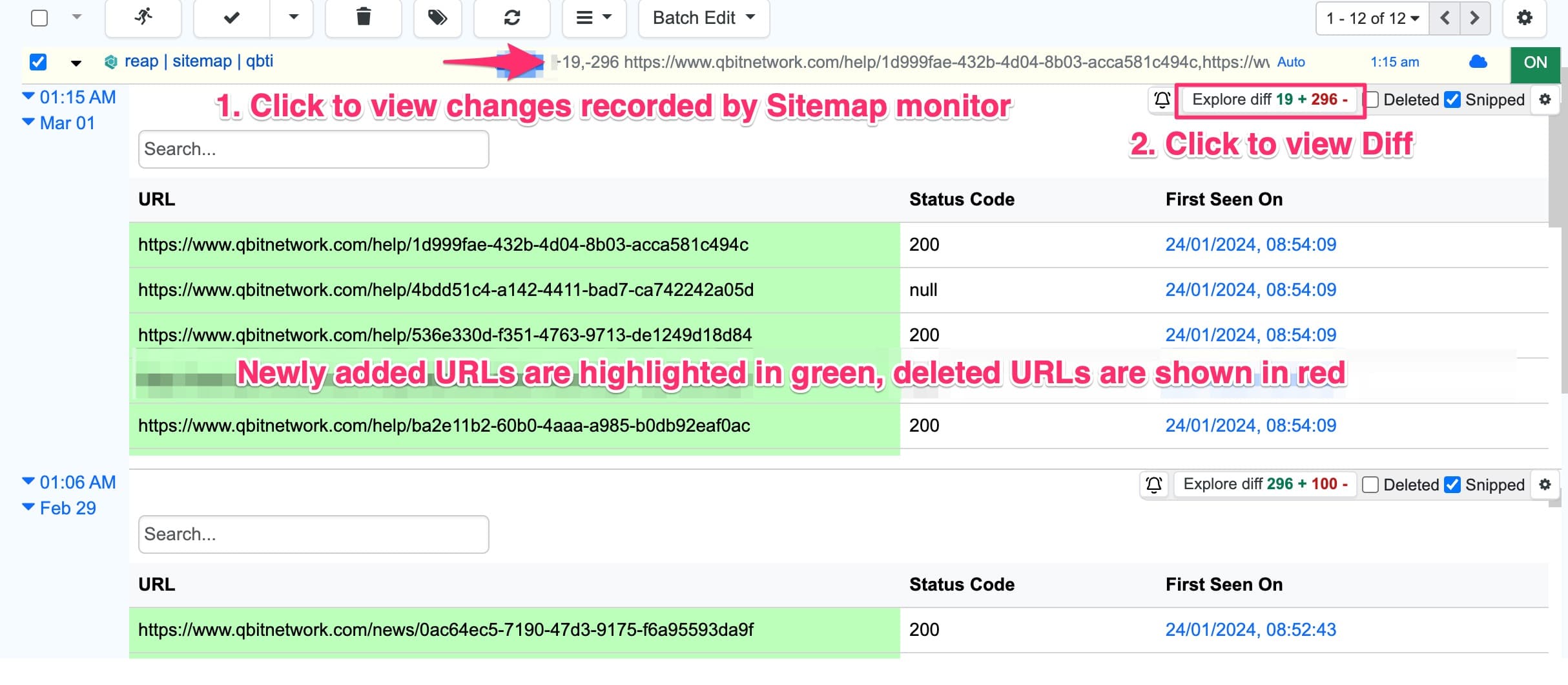
How to exclude links for crawling and monitoring?
You can use the regular expression filter to exclude links from crawling. This option is available on the source page when you first set up a crawler for sitemap monitoring. Alternatively, you can modify the configuration of any existing crawler from the detail page.
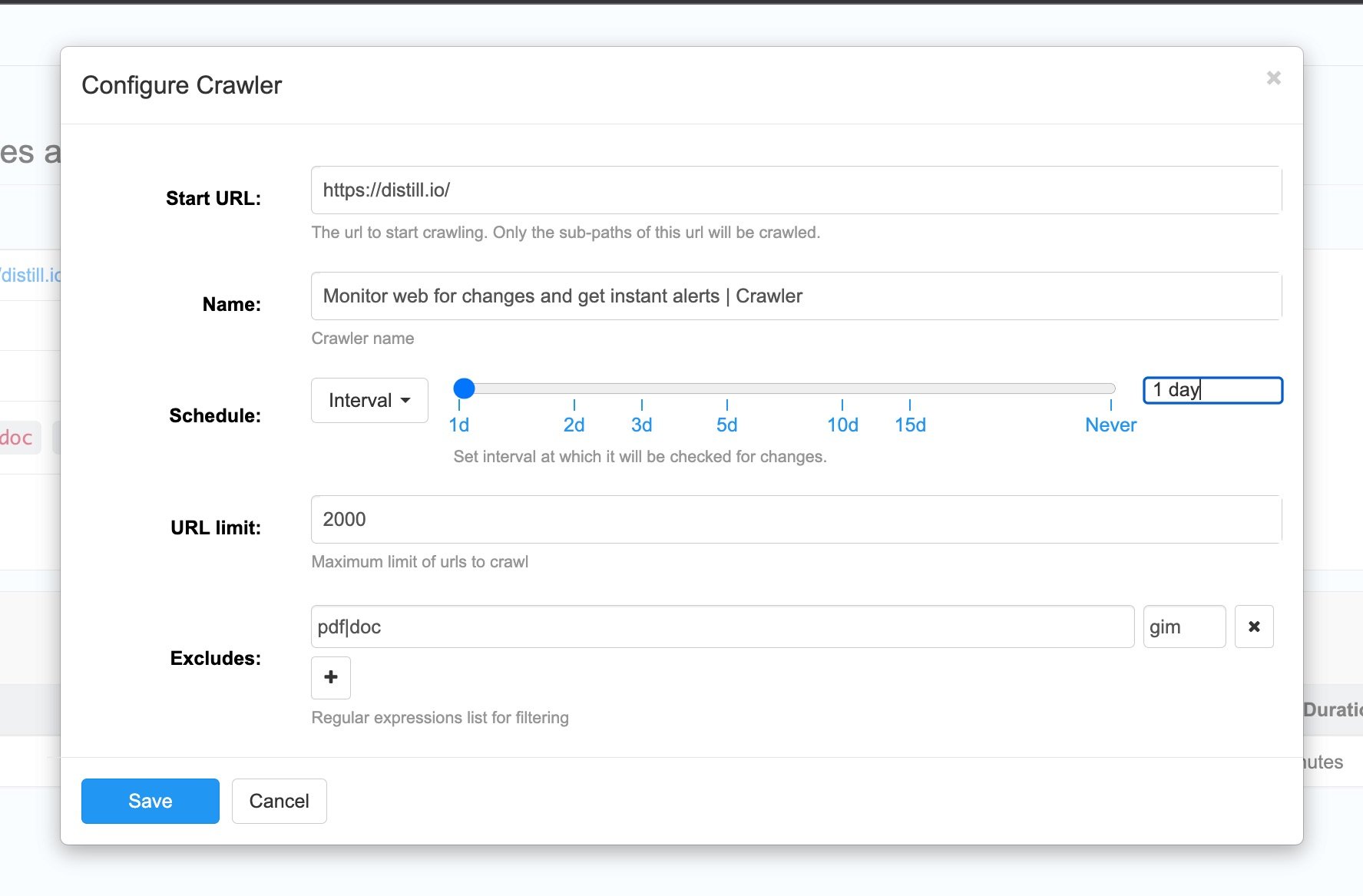
How to change the frequency of crawling?
By default, the crawler frequency is set to 1 day. However, you have the option to modify the crawling frequency according to your requirements. You can do this by navigating to the crawler’s page as shown below:
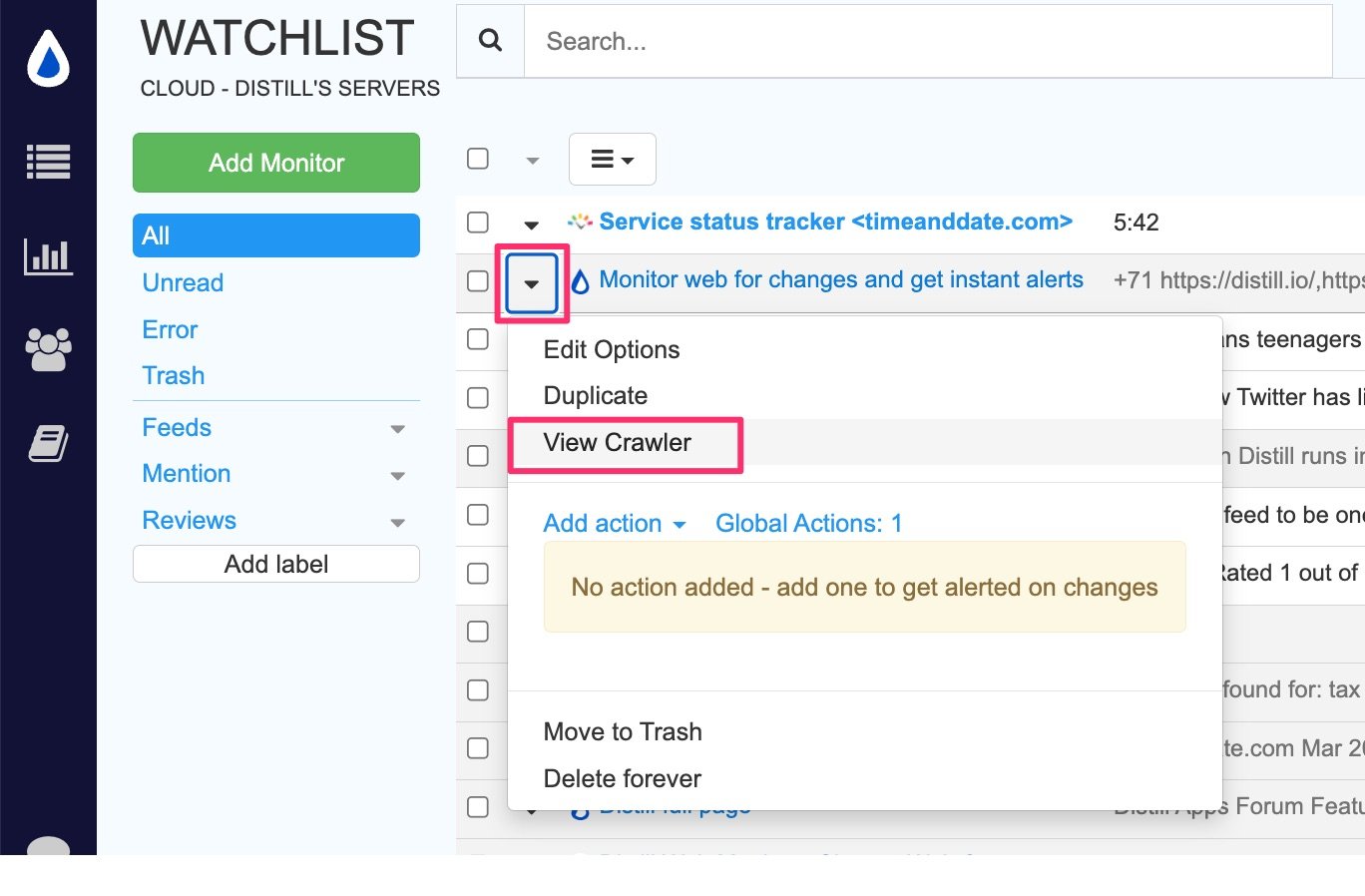
Then you can click on the “Edit Crawler” option and change the schedule.
How to view and manage crawlers?
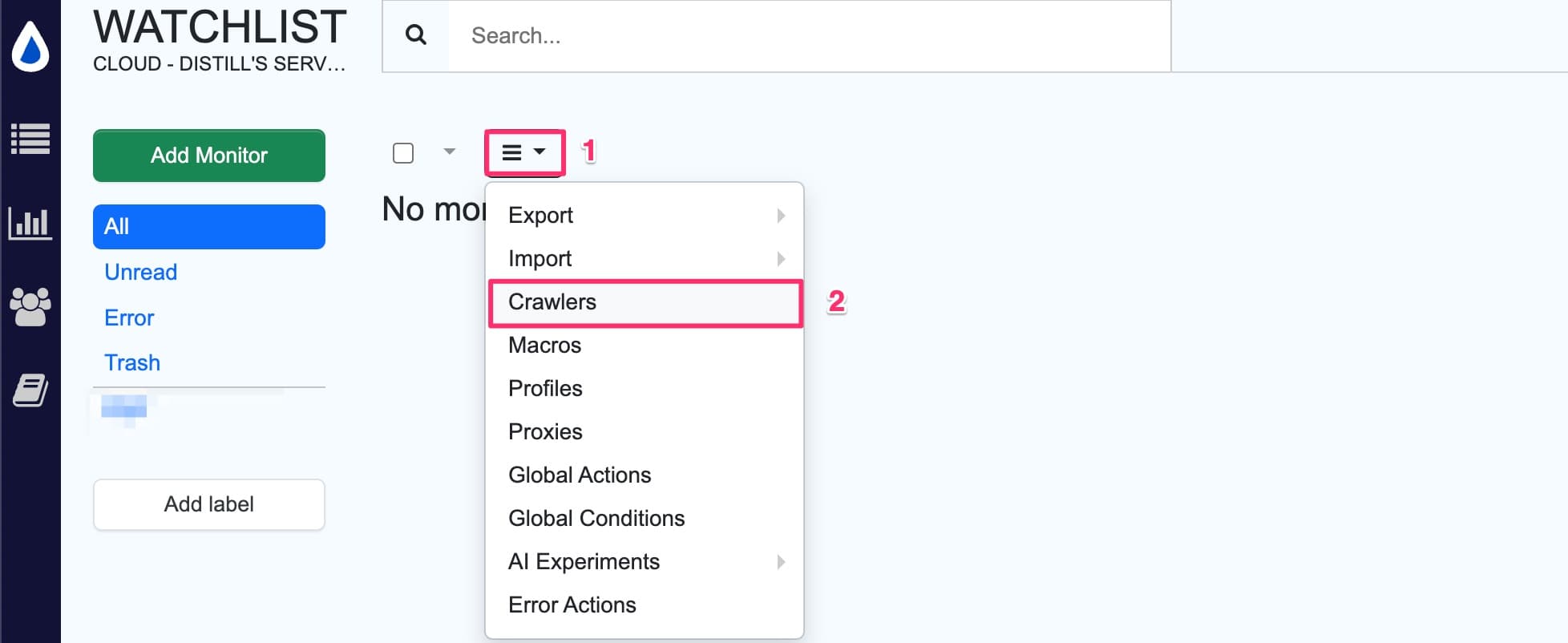
- Click the hamburger icon and select
crawlersfrom the drop-down.
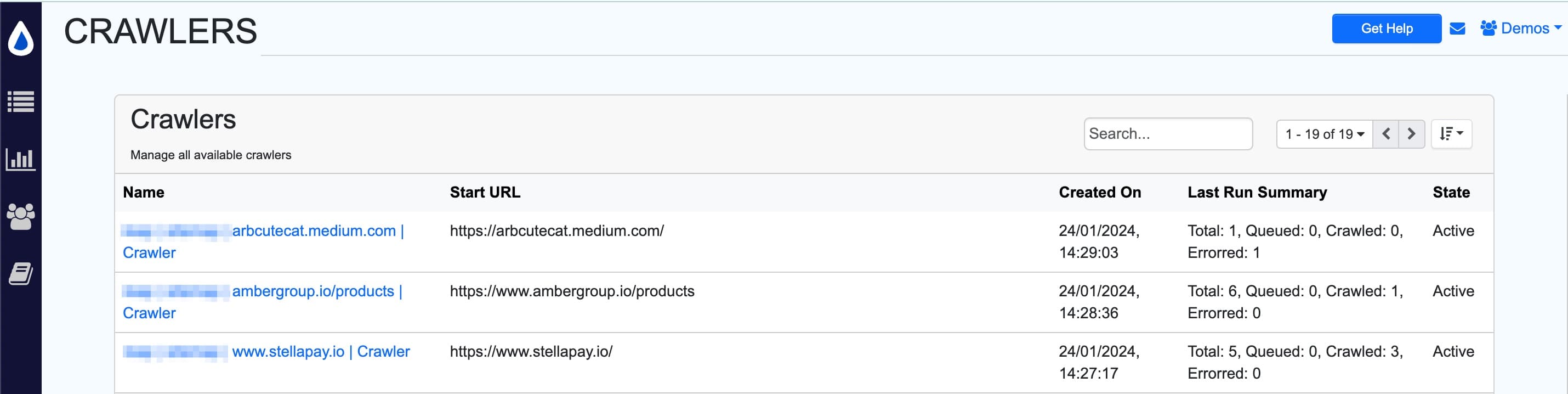
- The crawler list opens up. It has the details of the name of the crawler, start URL, created date, crawler summary and current state.
- Click on any crawler to view details and jobs run. You can even edit the crawler here.
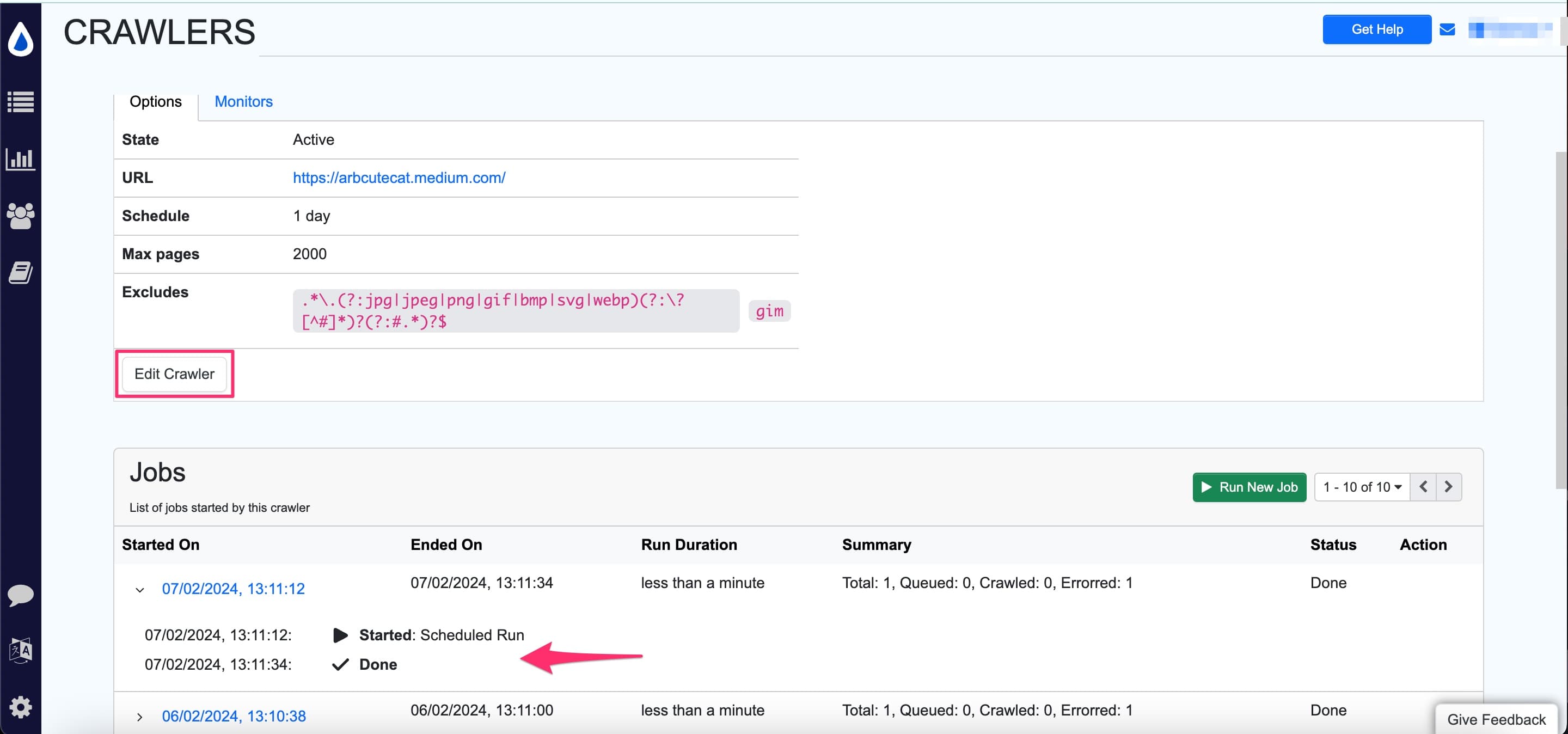
The jobs section shows all the crawler runs, including details of the total, queued, crawled and errored URLs.
| Crawler status | Description |
|---|---|
Total |
The total number of URLs found in the sitemap |
Queued |
The URLs waiting to be crawled |
Crawled |
The number of URLs that have already been successfully crawled |
Errored |
The number of URLs that encountered errors during the crawling process |
- In the crawler details view, you will see list of jobs run by the crawler. Here, click on the date field in the
Started Oncolumn.
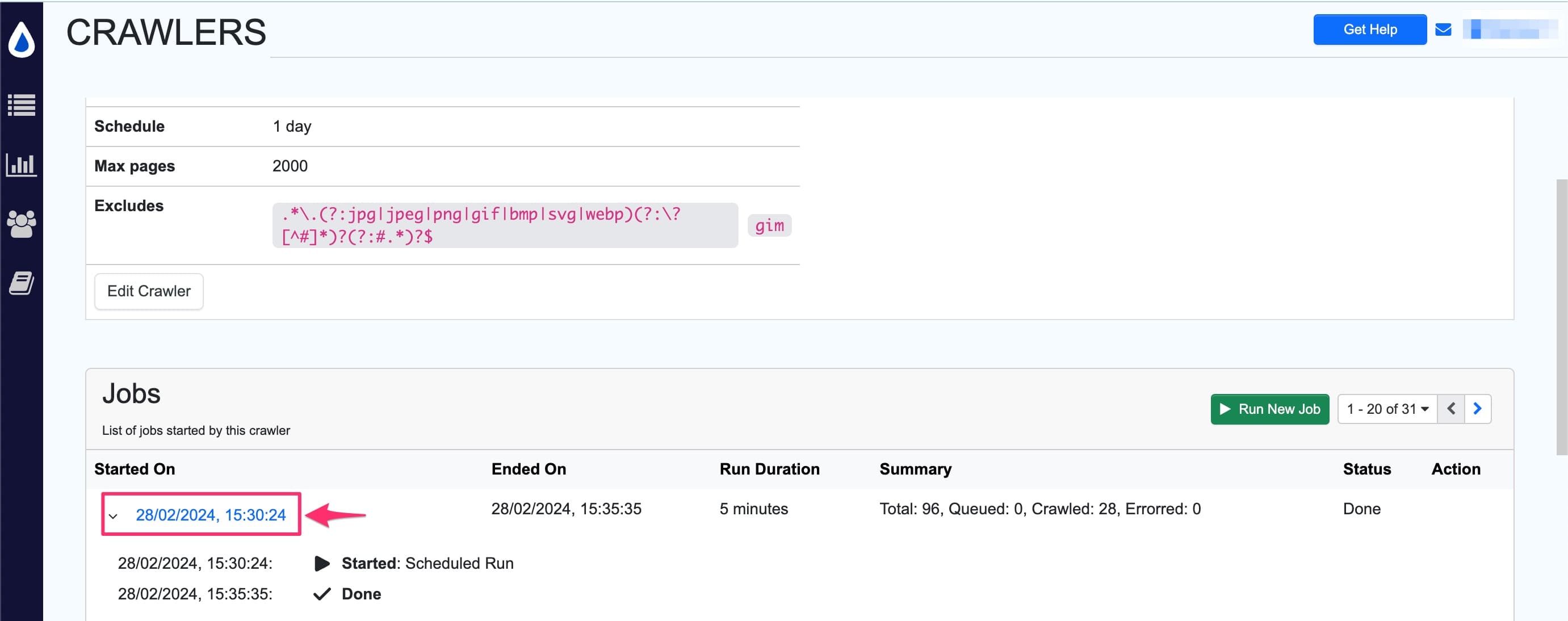
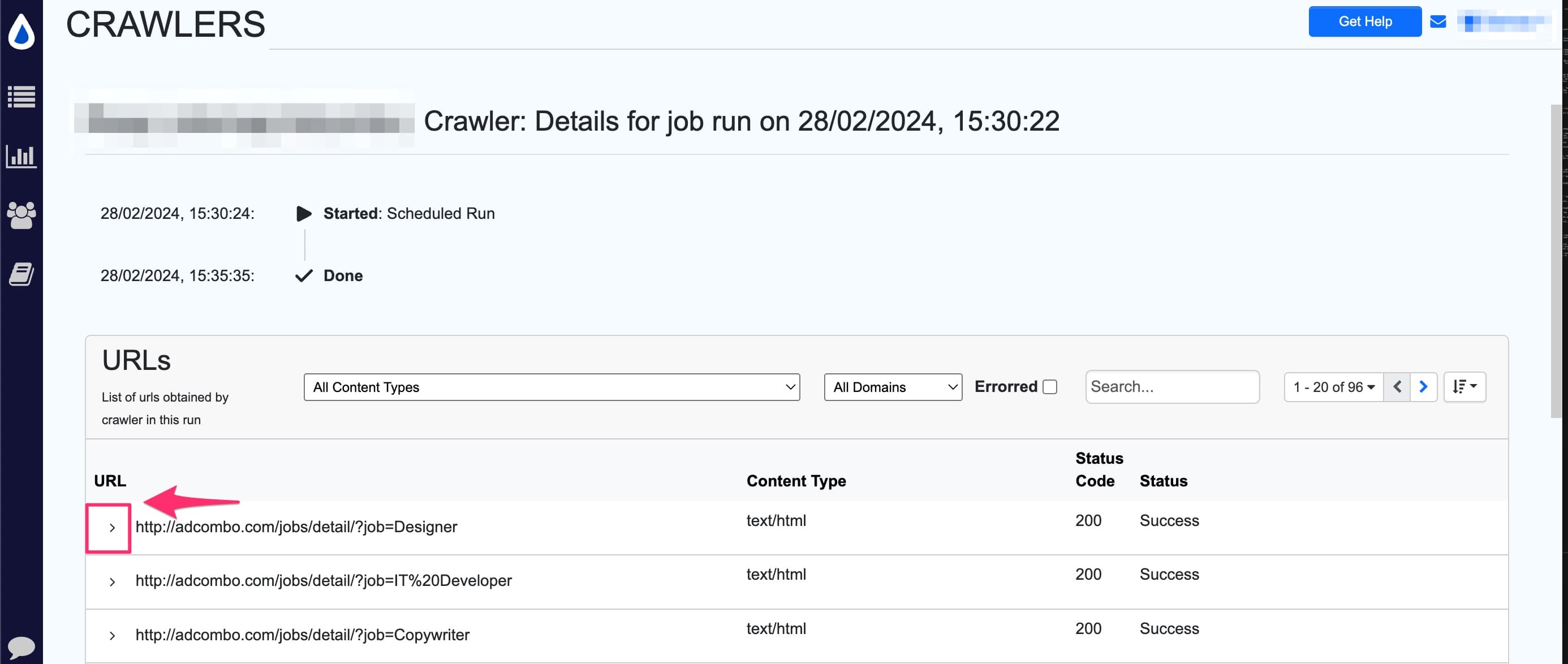
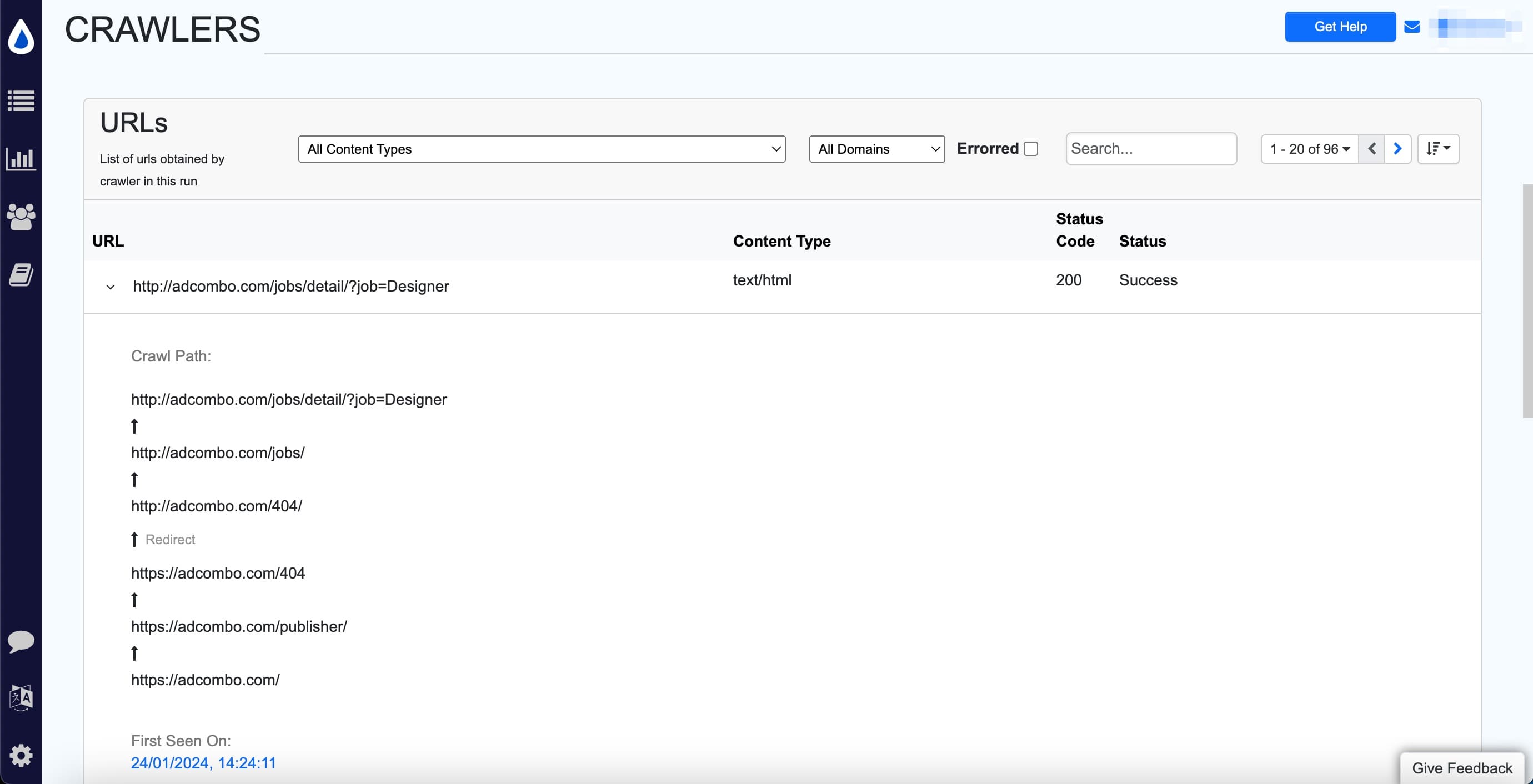
Now, the sitemap monitor will show the URLs found and its corresponding status. Click the Caret > icon to view the crawl path to the URL.
How is crawler data cleaned up?
The management of data within the context of crawlers involves the creation of jobs for each crawl. Given the potentially substantial volume of data generated by these jobs, a systematic cleanup process is implemented. Specifically, we retain only the latest 10 jobs, removing any excess data associated with previous jobs.
It’s important to note that jobs that have detected a change in the past are preserved, unless and until the preserved change history undergoes truncation. This ensures that users have access to historical job data that may have significance, even if it extends beyond the most recent 10 jobs.