Monitoring Sitemap of a Website Using a Crawler
Currently in alpha • Available in Professional plan and above
What is sitemap monitoring?
A sitemap helps search engines understand a website’s structure. While XML sitemaps are common, they’re often outdated or incomplete. Distill’s sitemap monitor uses a crawler to discover all pages on a website—even hidden or dynamically generated ones—and alerts you when URLs are added or removed.
How sitemap monitoring works
Distill’s crawler creates a comprehensive list of URLs by:
- Starting at your specified URL
- Finding all links on that page
- Following each link to discover more pages
- Repeating until all reachable pages are found
Crawling rules
The crawler will not follow:
- Links outside the website’s domain
- Links not in the same subdomain/subpath
- Links matching your exclusion filter
Example: Starting at https://distill.io will crawl https://distill.io/blog and https://distill.io/help, but not https://forums.distill.io (different subdomain).
Two-step workflow
- Crawling — Discovers all links on a website and creates a sitemap. Configure crawl frequency and exclusions at this stage
- Monitoring — Import discovered URLs from the sitemap into your watchlist to monitor their content
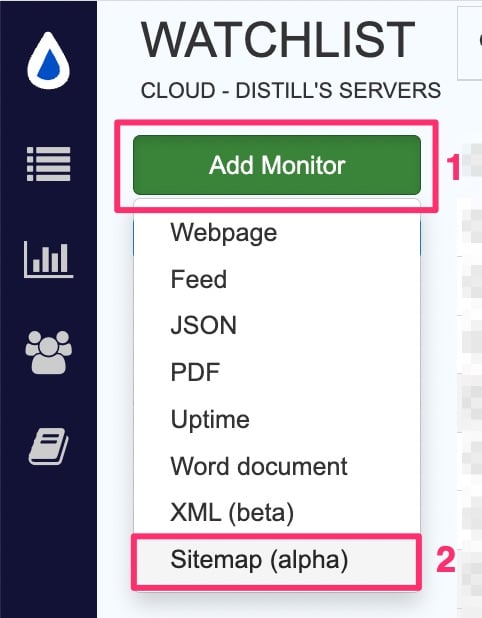
Create a sitemap monitor
-
Open the Watchlist at https://monitor.distill.io
-
Click Add Monitor → Sitemap
-
Enter the Start URL
The crawler will follow links within the same subdomain and subpath only.
Example:
https://distill.iowill crawl:- ✅
https://distill.io/blog - ✅
https://distill.io/help - ❌
https://forums.distill.io(different subdomain)
- ✅
-
(Optional) Add a regular expression filter to exclude specific links
-
Click Done to open the Options page. Configure actions and conditions, then save
You’ll receive alerts whenever URLs are added or removed. Click the monitor preview to view change history.
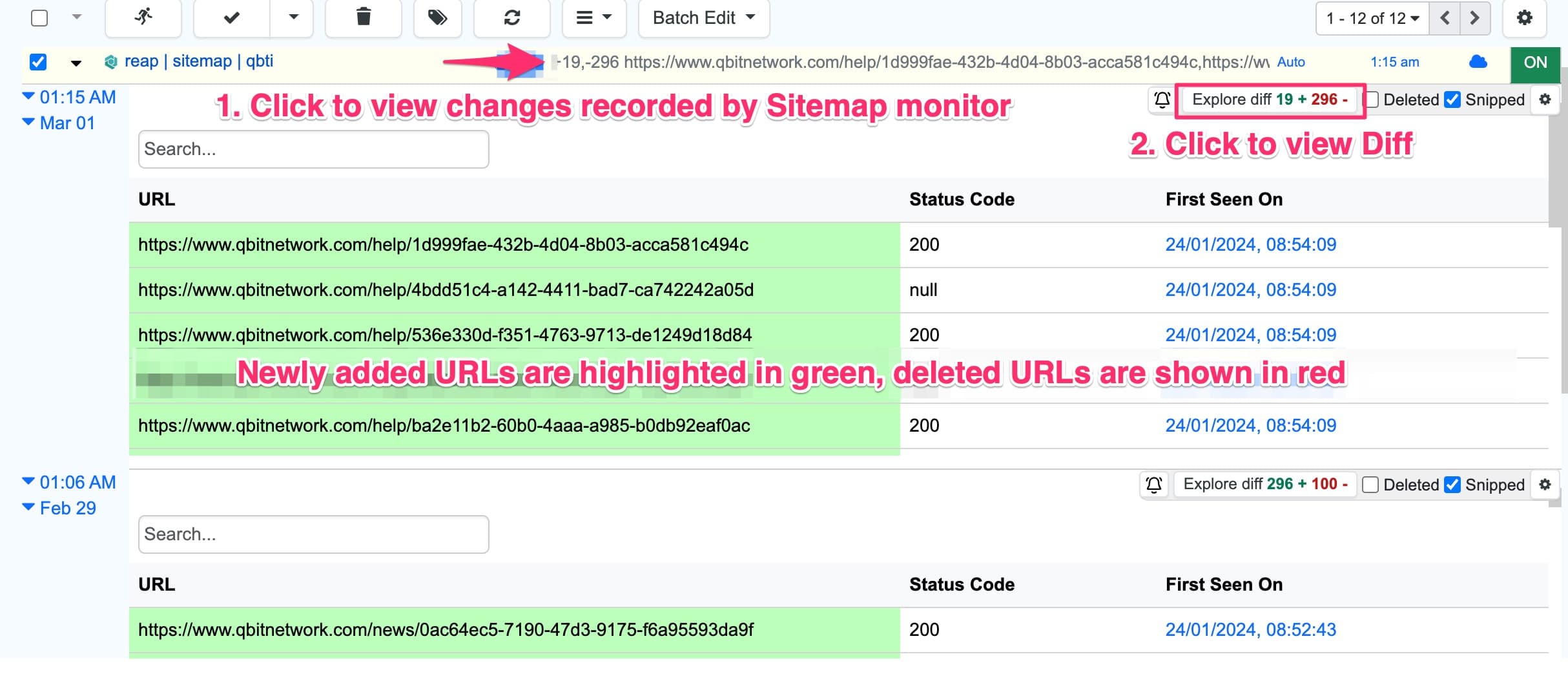
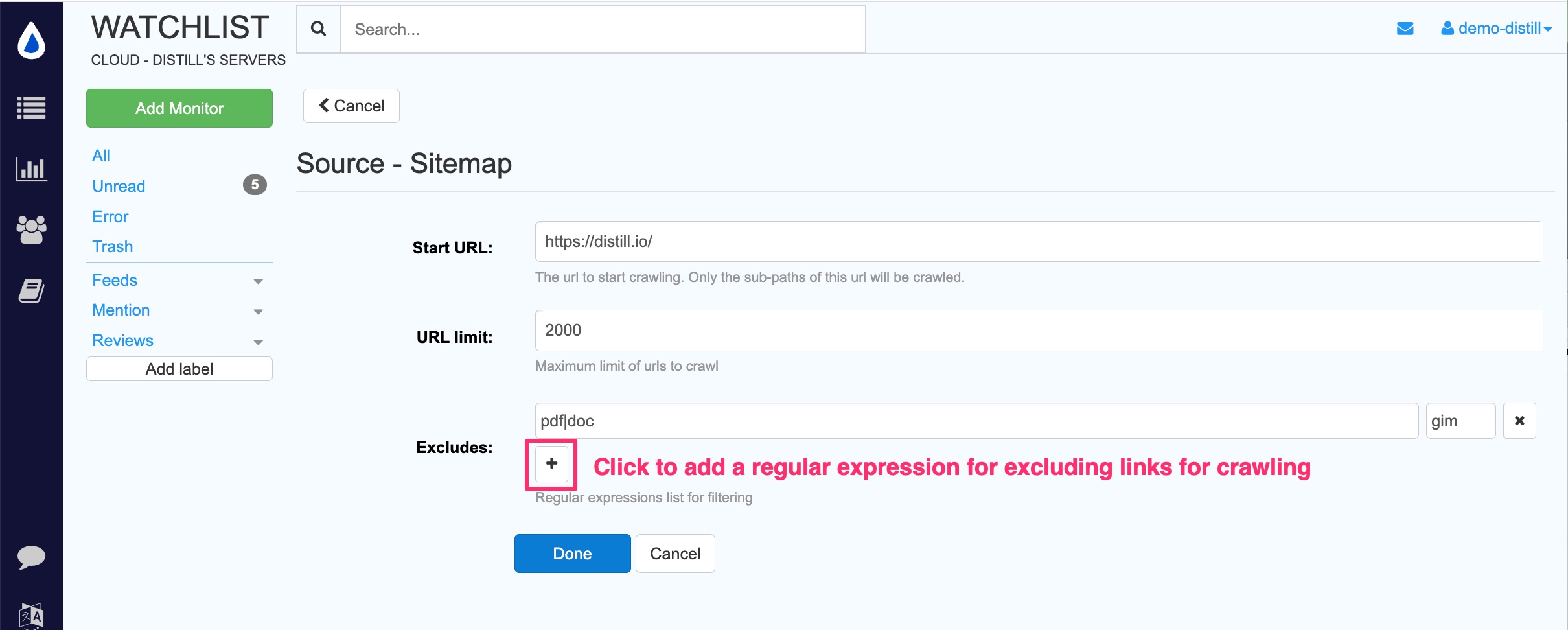
Exclude links
Use regular expressions to exclude specific links from crawling. Image links are excluded by default.
Add the filter when creating the monitor or edit it later from the crawler detail page.
Crawl frequency
The default crawl frequency is once per day. To change it:
- Click the hamburger menu → Crawlers
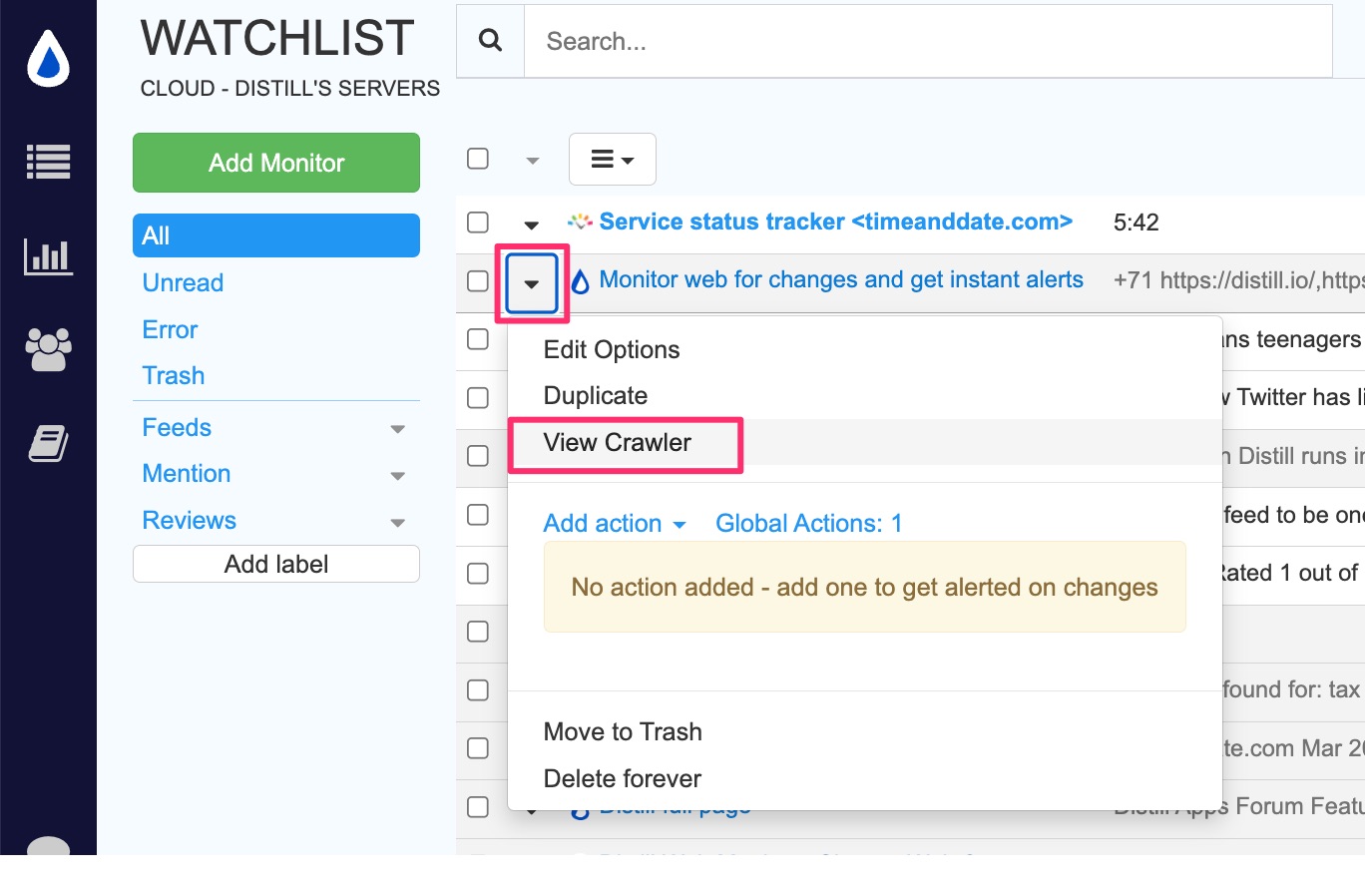
- Select your crawler and click Edit Crawler
- Modify the Schedule settings

Page macros
Page macros run validation steps on each page before crawling. Use them to prevent errors or skip irrelevant pages.
Add page macros
- Click the hamburger menu → Crawlers
- Select your crawler → Edit Crawler
- Next to Page Macros, click Edit Steps
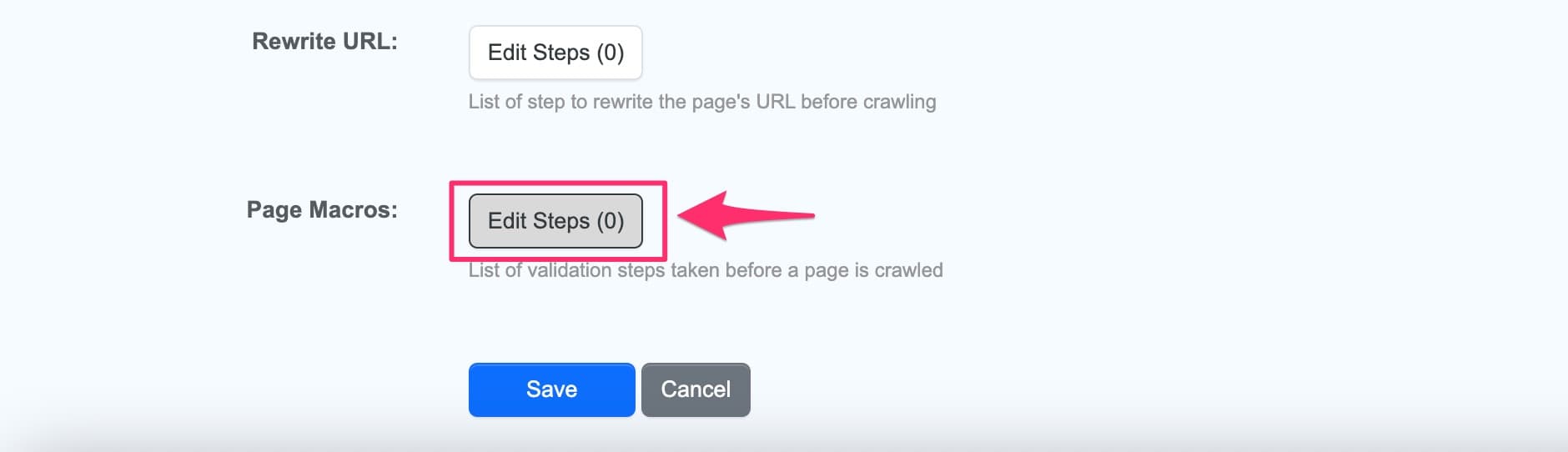
- Add the steps to execute before crawling each URL
Use case: Stop crawling when site is down
When a site returns 503 errors (temporarily unavailable), pages won’t contain the original links. Crawling them creates an incomplete list and triggers false alerts. Use a page macro to stop the crawl:
- Add an
assertstep and expand the options - Check if
element_has_textcontains keywords like “Maintenance” - Click Set optional Arguments and add an error message: “Crawler stopped: Site under maintenance”

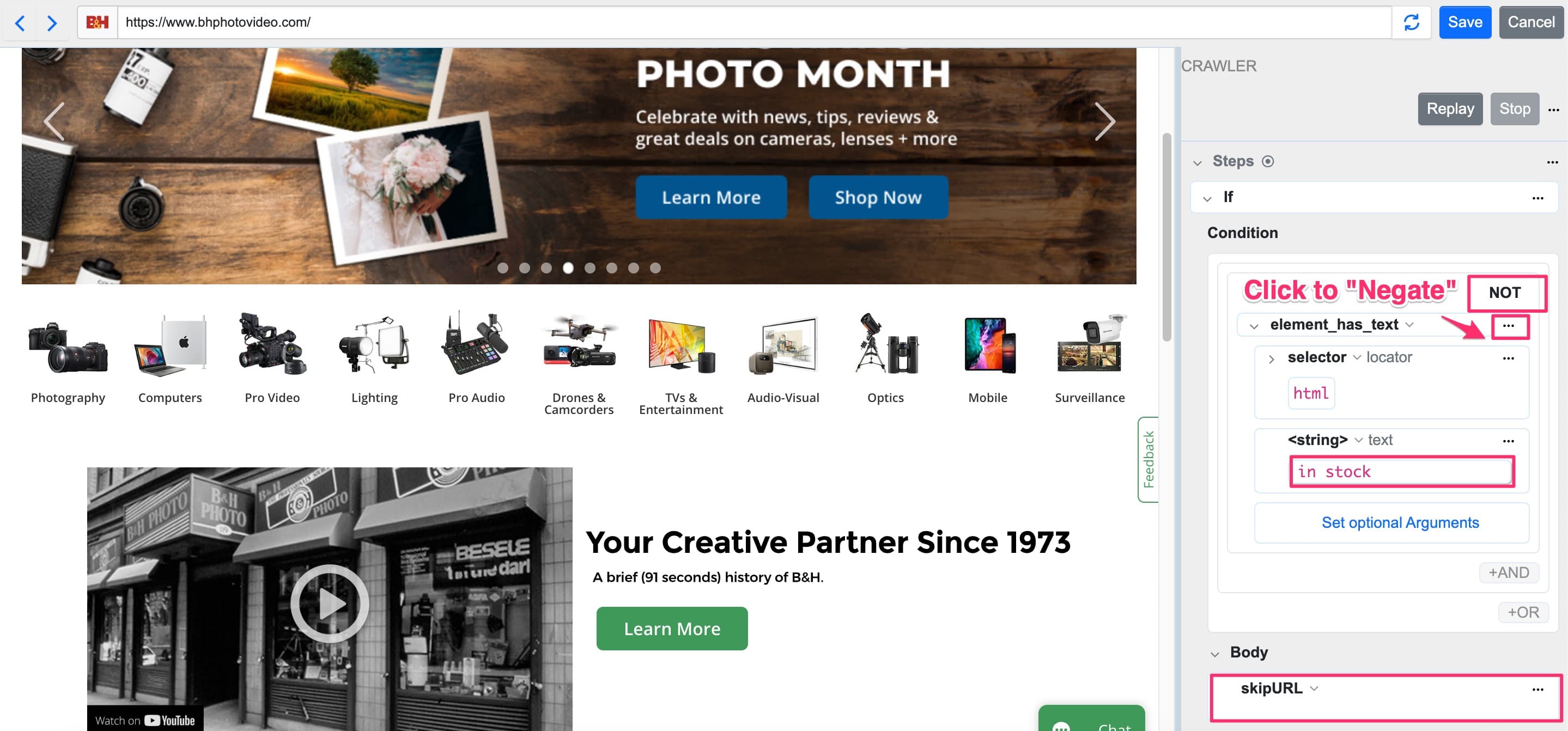
Use case: Skip URLs based on content
Skip irrelevant URLs to avoid unnecessary notifications. For example, skip out-of-stock products:
- Add an
if...elseblock - Check if
element_has_textcontains “in stock” and negate this step using the overflow button (addsNOT) - In the condition body, use
skipURL
This skips all URLs that don’t contain “in stock”.
URL rewrite
URL rewriting normalizes URLs before crawling to prevent duplicates. Use it to:
- Consolidate URLs with different parameter orders
- Remove unnecessary query parameters
- Manage redirects
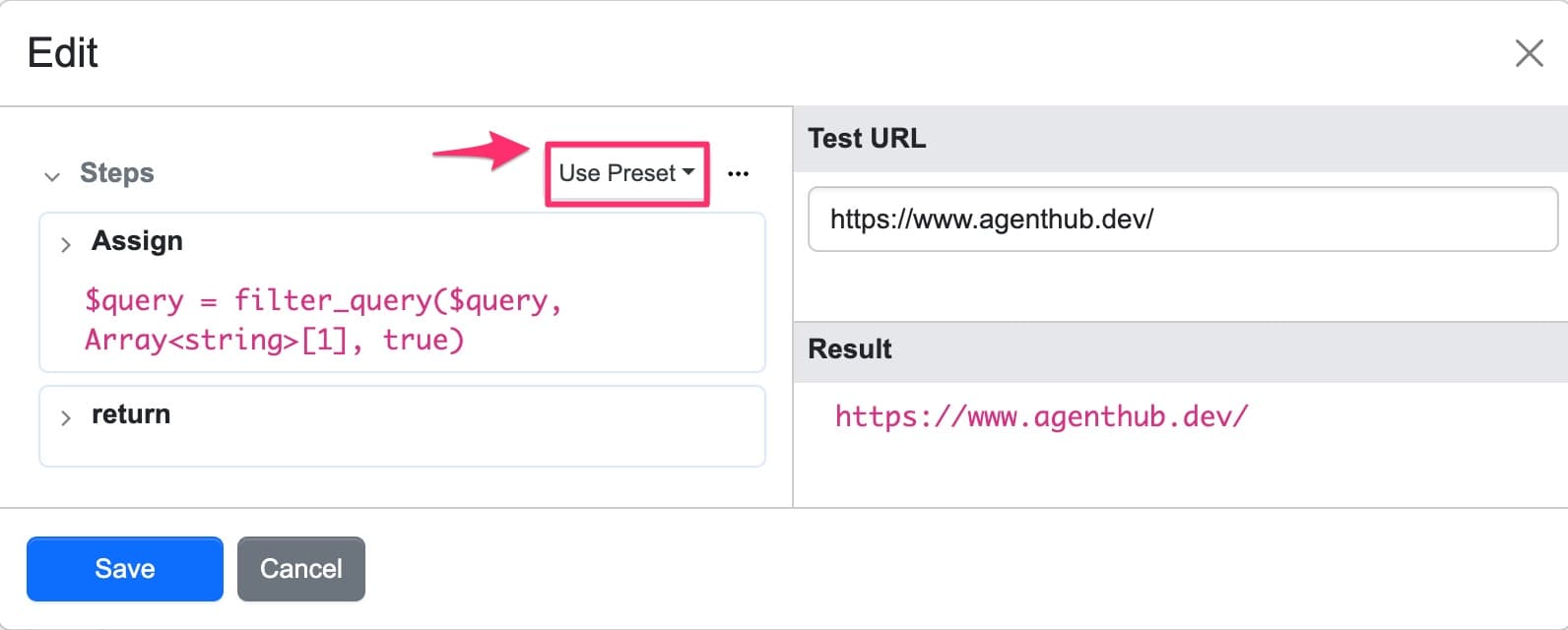
Rewrite presets
Example URL: https://example.com/products?size=10&color=blue&category=shoes
-
Sort query parameters — Alphabetically sorts parameters
Result:
https://example.com/products?category=shoes&color=blue&size=10Must use with “Return constructed URL” preset
-
Remove all query parameters — Strips all parameters
Result:
https://example.com/products -
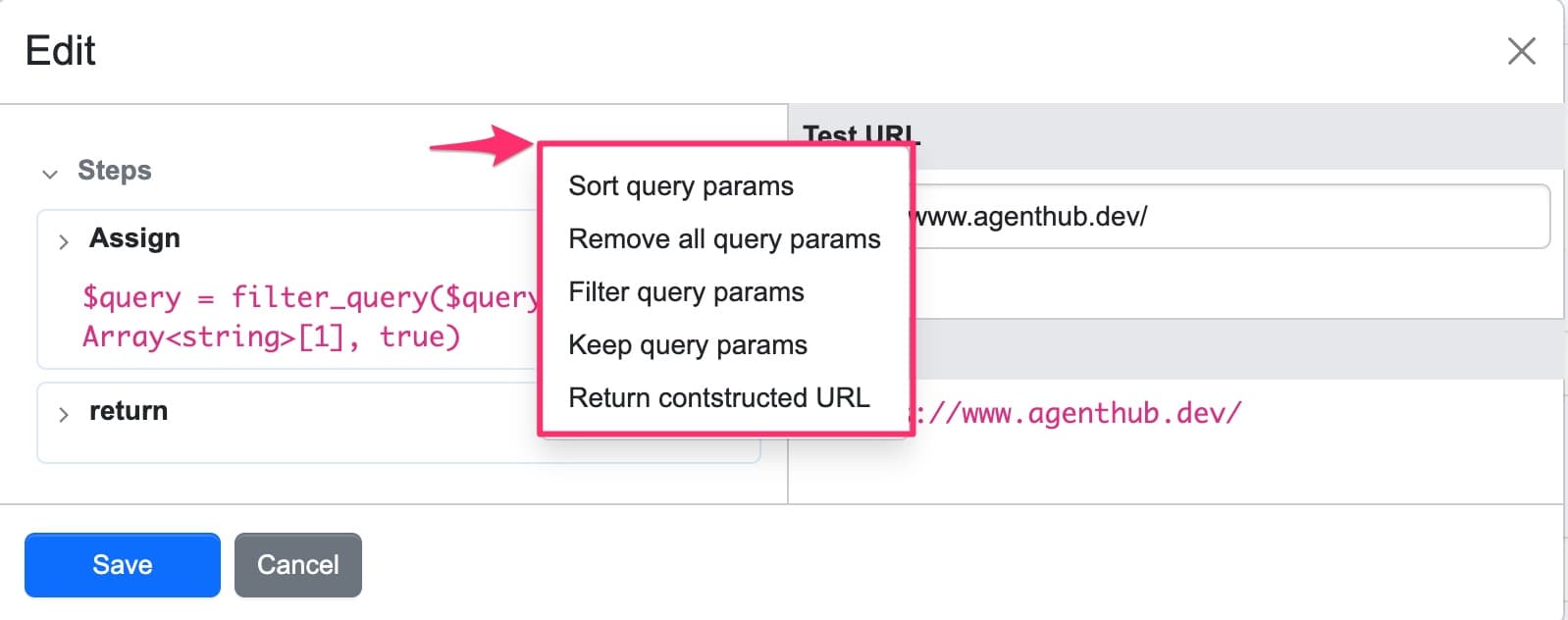
Return constructed URL — Returns the reconstructed URL
Configure URL rewrite
- Select your crawler and click Edit Crawler
- Next to URL Rewrite, click Edit Steps

- Select your desired presets
Use case: Eliminate duplicate URLs
URLs with different parameter orders can appear as different pages, causing false duplicate alerts.
Example: These URLs lead to the same page:
https://bookstore.com/search?sort=price_asc&category=fictionhttps://bookstore.com/search?category=fiction&sort=price_asc
Normalize them by sorting parameters:
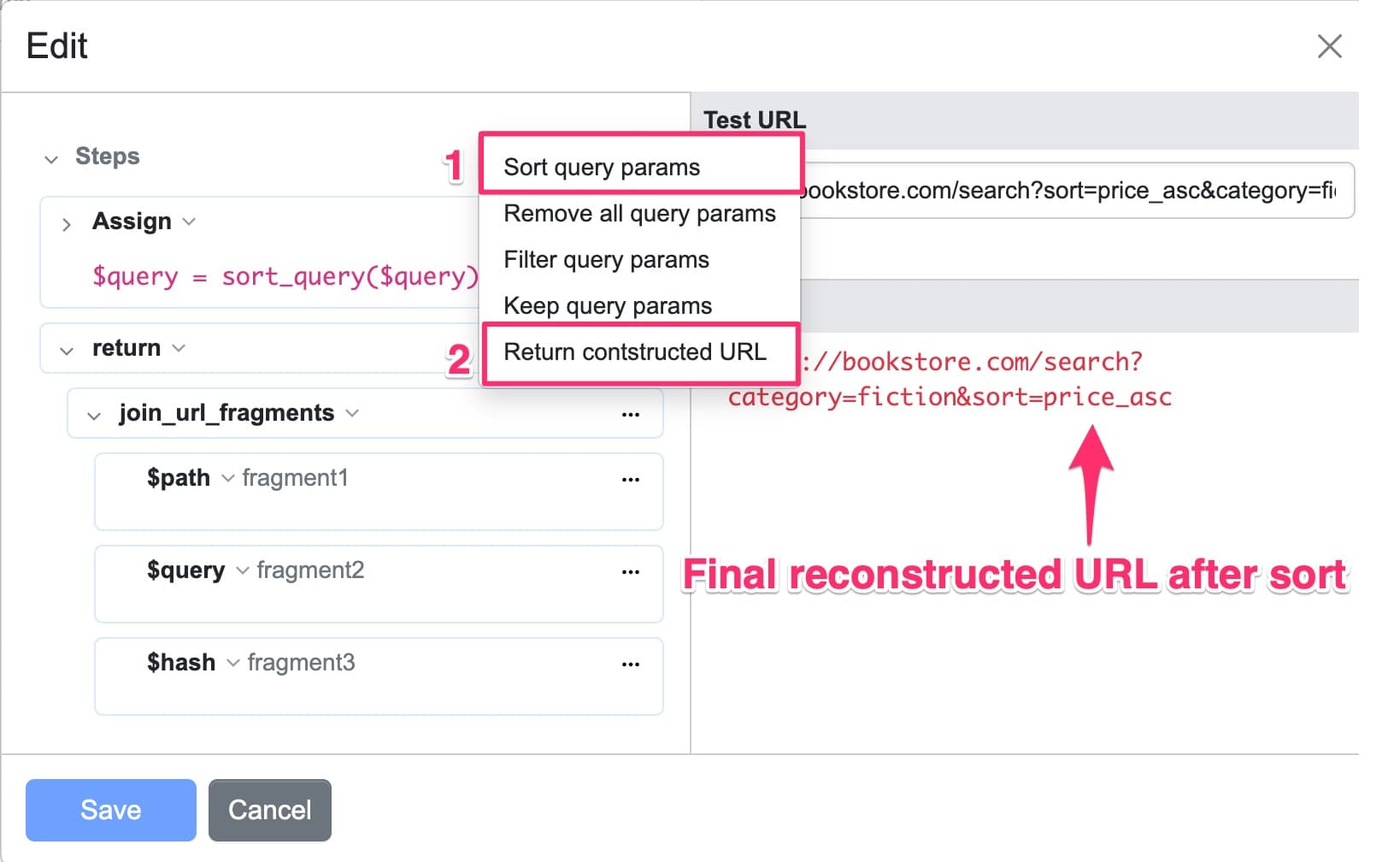
- Click Edit Steps in URL Rewrite
- Select Sort Query Params
- Select Return Constructed URL
The crawler now treats both URLs as the same entry.
Manage crawlers
View all crawlers
- Click the hamburger menu → Crawlers
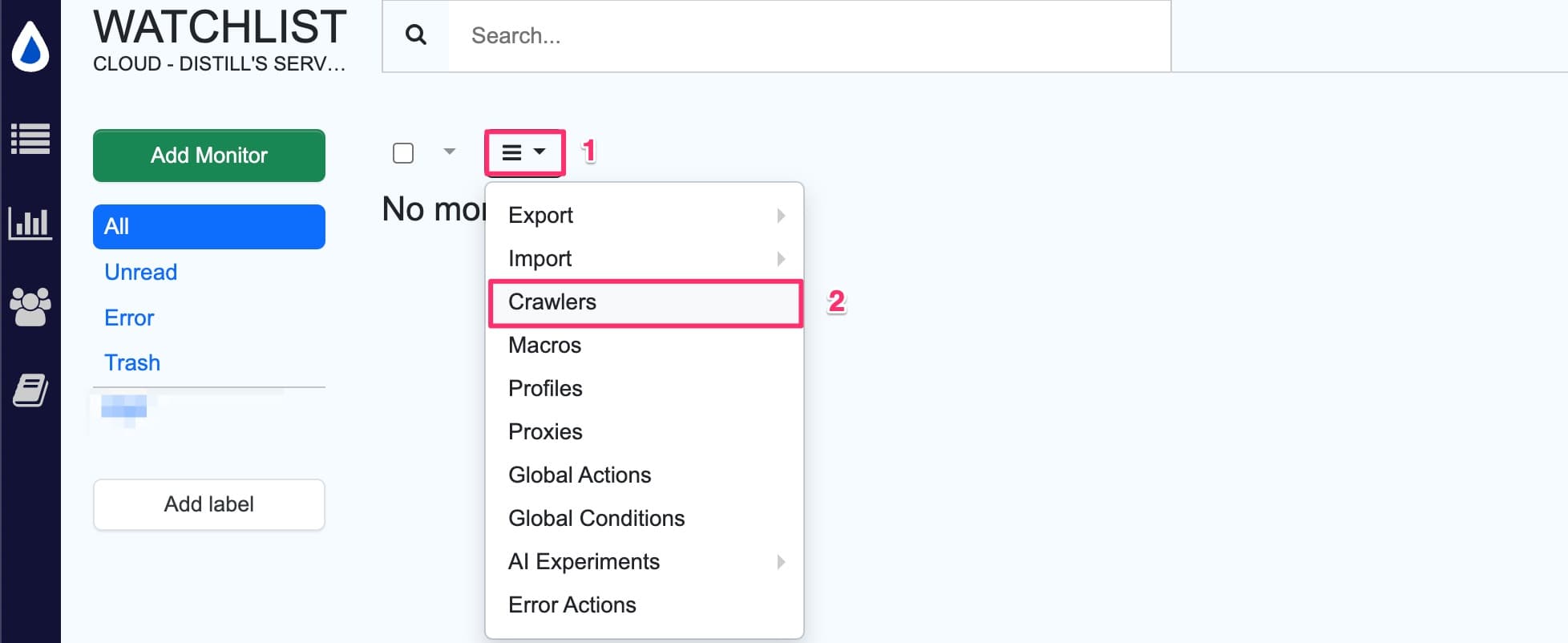
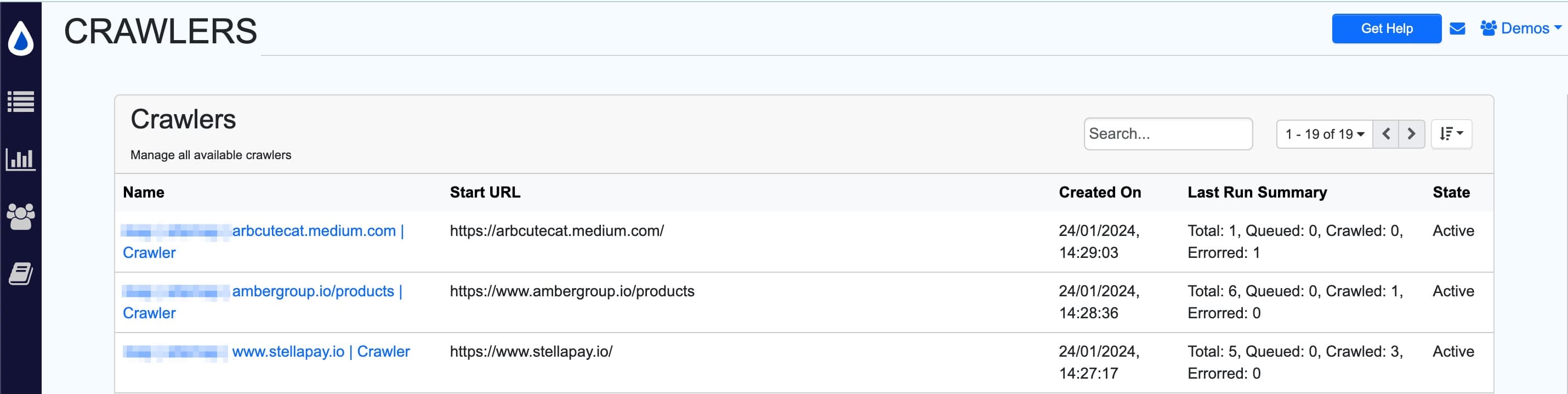
- View crawler details: Name, Start URL, Creation date, Last Run Summary, and State
View crawler jobs
Click any crawler to see its job history. Click Edit Crawler to modify schedule, exclusions, page macros, or URL rewrite settings.
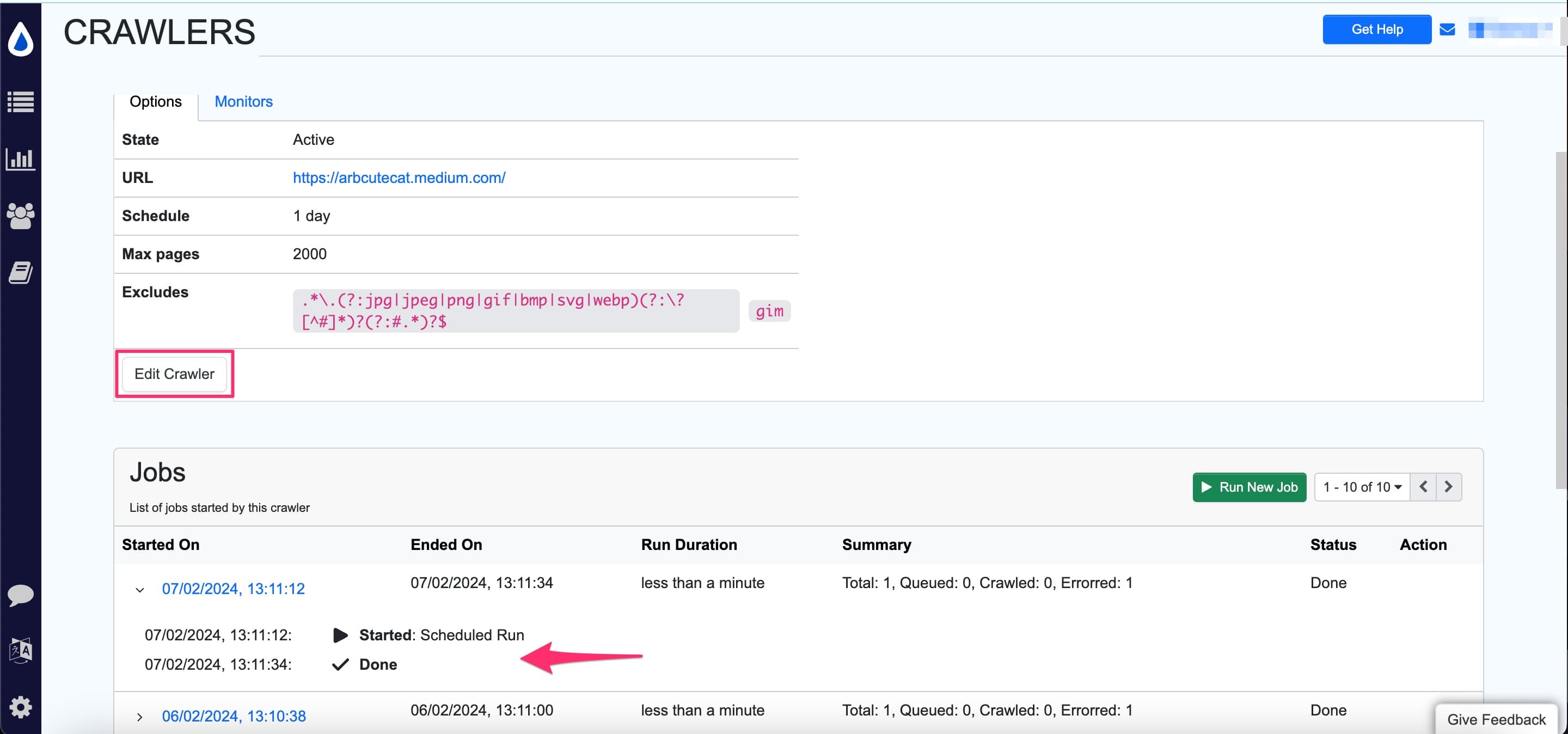
Job statistics:
| Status | Description |
|---|---|
| Total | Total URLs found in the sitemap |
| Queued | URLs waiting to be crawled |
| Crawled | Successfully crawled URLs |
| Errored | URLs that encountered errors |
View crawl details
Click the Started on field for any job to see the list of discovered URLs and their crawl status.
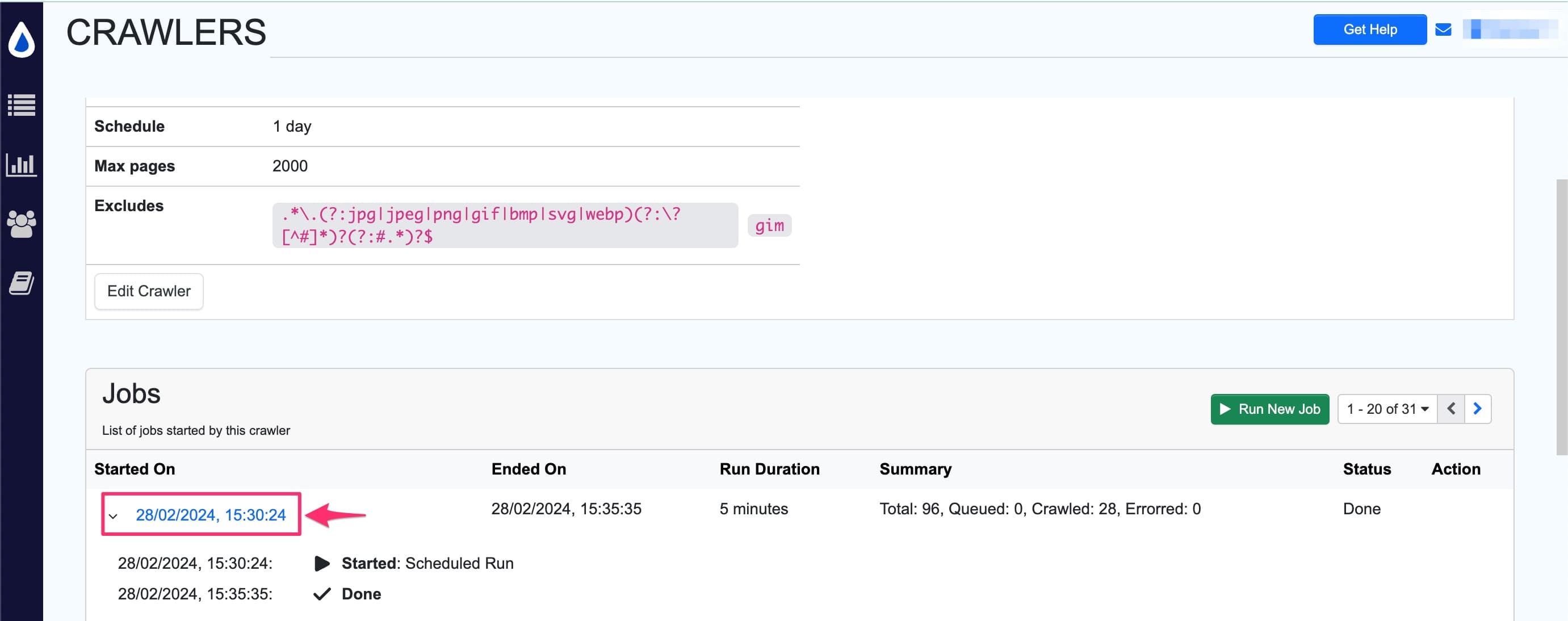
Click the caret > icon next to a URL to view its crawl path.
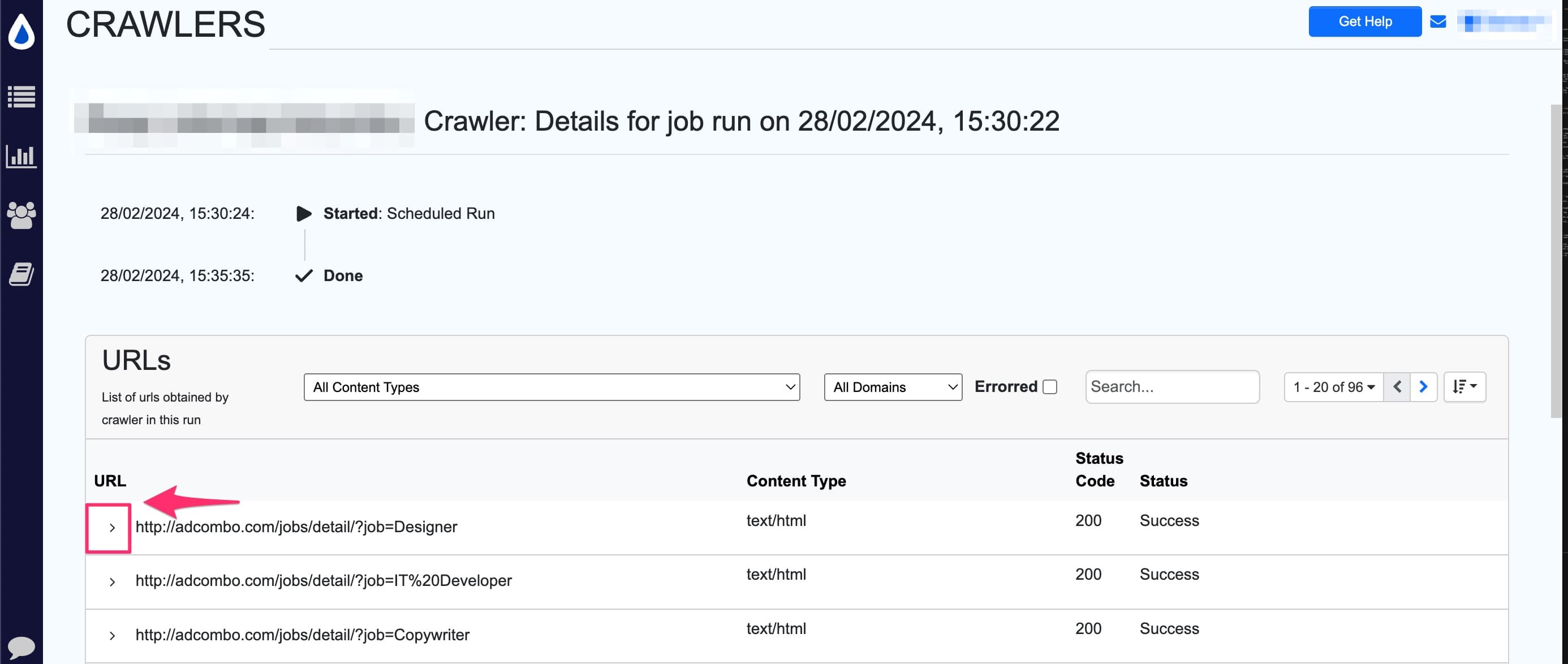
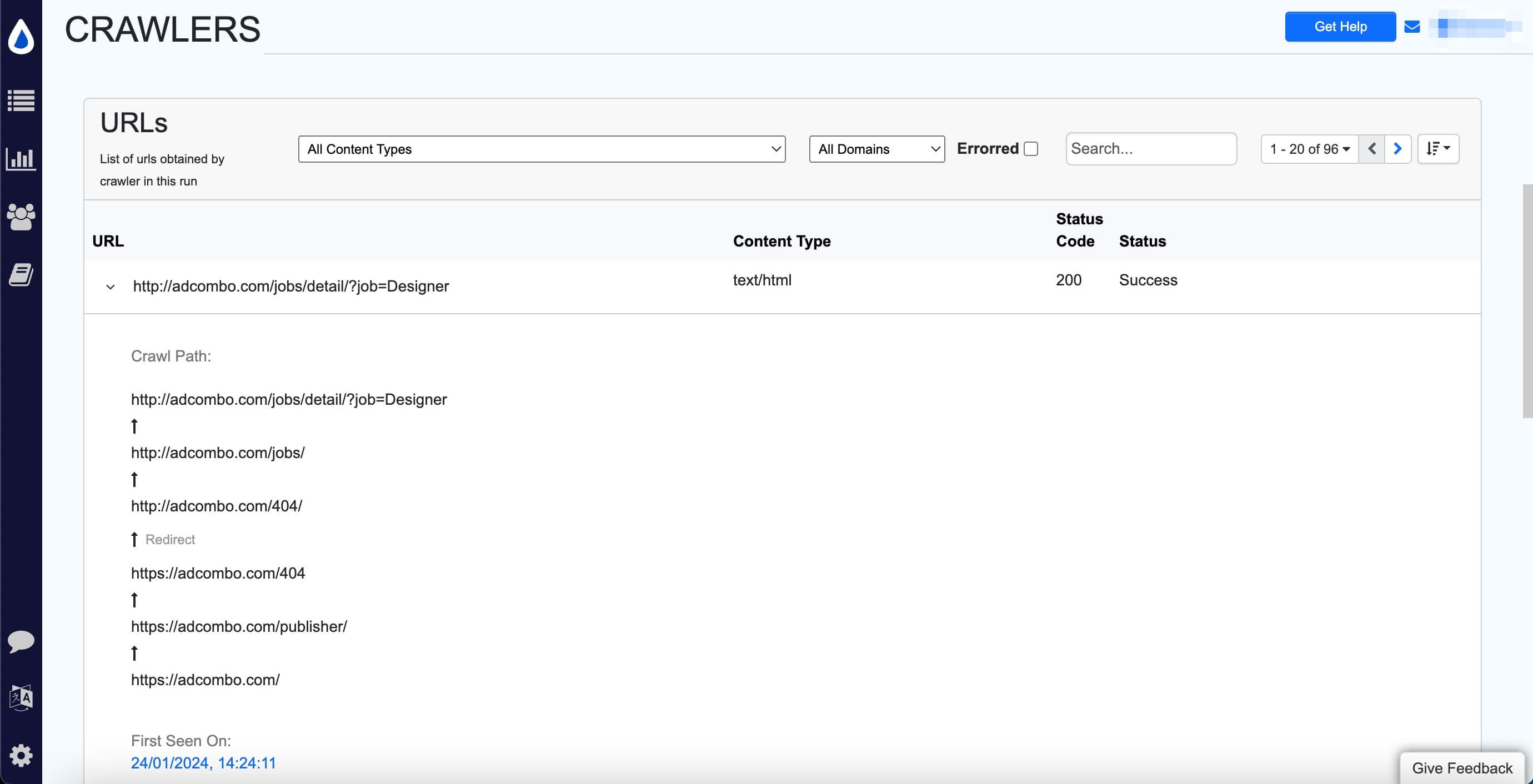
Import crawled URLs
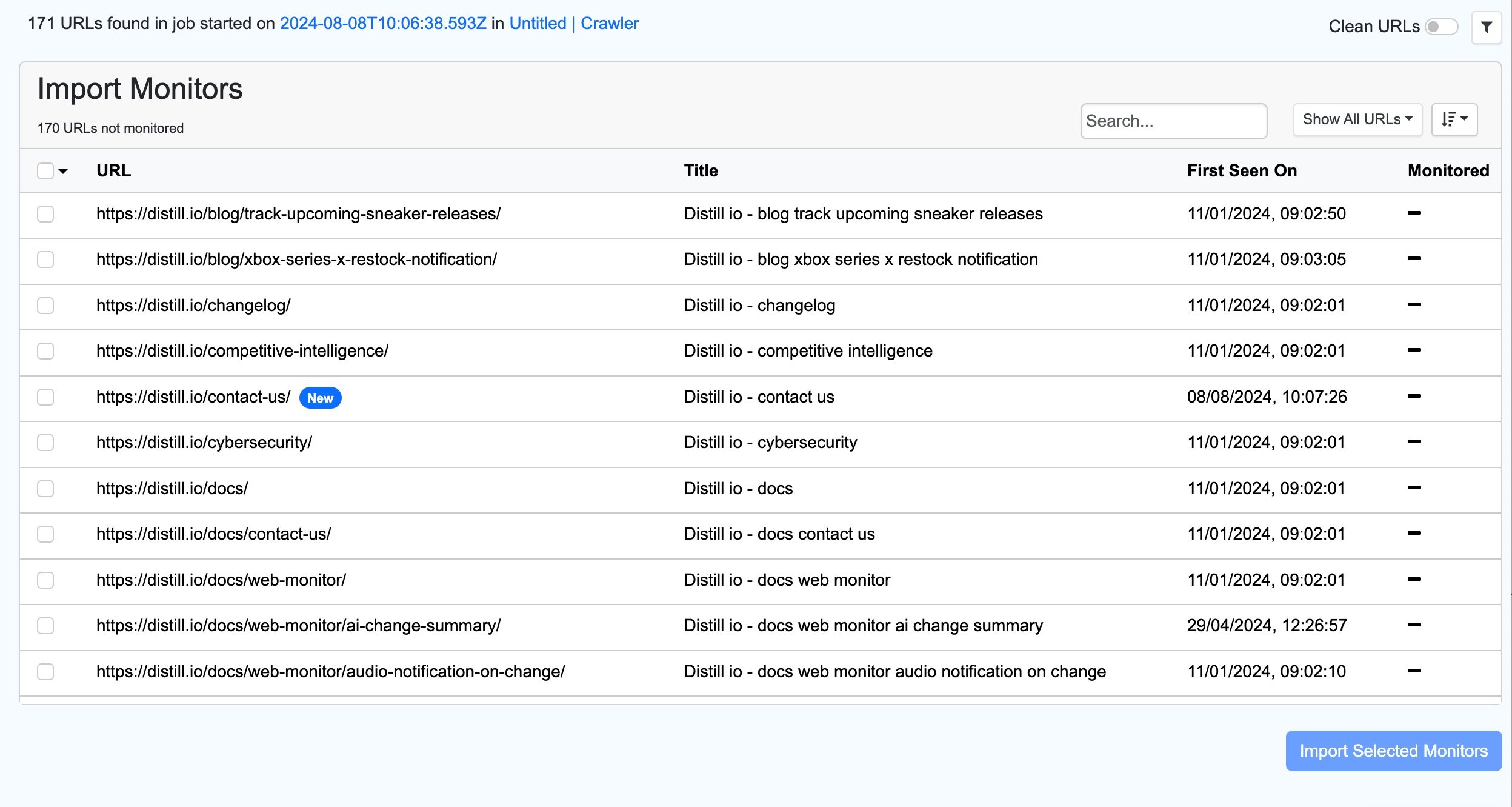
After crawling completes, import discovered URLs into your watchlist to monitor their content.
- Open the sitemap monitor’s Change History
- Click Import Monitors

- View the list of crawled URLs with their details
- Filter by Show All URLs to see only unmonitored URLs
- Select the URLs you want to monitor
- Click Import Selected Monitors and configure the options
Export crawled URLs
Export the list of crawled URLs to CSV:
- From your watchlist, click the sitemap monitor’s preview
- Click Download
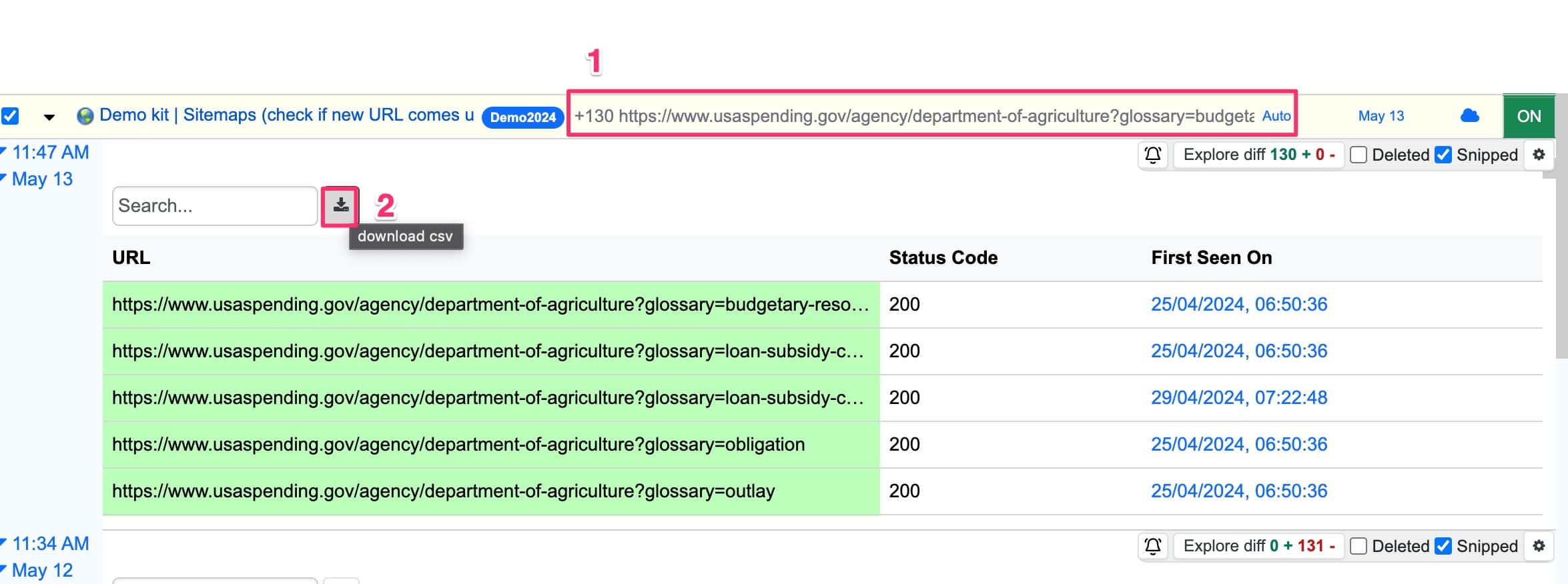
CSV fields:
- URL — The discovered URL
- Content Type — Resource type
- Status Code — HTTP response code
- Diff Type — Change status:
- Addition — Newly found URL
- Unchanged — URL present in previous crawl
- Deleted — URL removed since last crawl

Data retention
Crawler jobs generate significant data. To manage storage:
- Only the latest 10 jobs are retained
- Jobs that detected changes are preserved until change history is cleared
- Older jobs without changes are automatically removed
This ensures access to important historical data while managing storage efficiently.